Pathfinding
• 15 min read
Intro
With some spare time that I had, I wanted to learn about path finding algorithms and data structures that come with them. I always thought it was an interesting problem, and I wanted to understand the empirical tradeoffs, optimizations, and generally see these in action.
| Algorithm | Data Type | Guaranteed Optimal Path? |
|---|---|---|
| DFS | Stack | No |
| BFS | Queue | Yes |
| DFS - Heuristic | Stack | No |
| Greedy Best-First Search | Priority Queue | No |
| A* | Priority Queue | Yes |
Defining the Problem Space
For this analysis, I assume an grid, where we only allow for orthogonal movement (up, down, left, right). We assume an unweighted graph. We define a starting point and an ending point, and the goal is to discover a single path that connects the 2. In this analysis, it is guaranteed that at least 1 solution exists, given how I'm generating the grids. A grid is simply defined as a matrix of 0's and 1's, with 0's denoting "blocked" nodes.
Whenever the term "distance" is used, it means the Manhattan Distance, as we are only using Orthogonal Movement, and it suits the problem space.
Generating the Grids
I used 3 (3.5?) distinct methods to generate grids for this analysis. One is random grids (I use 2 methods for this), one is fixed variants, and one is a maze.
Random Grids
I take 2 approaches, that really do not differ too much, on average. For each method, we can pass a percent_blocked parameter , which will dictate how many "blocked" nodes exist. Really, the upper bound of 1 is quite generous, which I'll explain, and I never exceed 0.6 in this analysis. I don't like to describe the varying blockage as a measure of "difficulty", as each pathfinding algorithm behaves differently. Also, this percent increases, there are less possible paths. I'll use the term "sparsity" to describe these, instead.
Approach 1
Randomly select a start point, then an end point. They're independent in the sense that they won't be identical, but the ending position is completely independent of the distance from the starting position.
For each node in the grid, block it with probably . Assert that there exists a valid path. If not, unblock the node, and move onto the next one. Do this until all nodes are iterated through.
Approach 2
Randomly select a starting point. Add this position to a Stack and initiate a "random walk", such that no node is ever re-visited. Continue this random walk until a distance of is reached. This value was selected because, if the random starting point was in the middle, then we want the ending point to be "as far away as possible", being the corner.
If the random walk reaches a place where there are no available moves left, but the distance was not achieved, then we pop from the stack (backtrack), and continue. Once this distance is achieved, we allow for a 75% chance of allowing for an extension of this path for each proceeding move.
Once this path is defined, we take a similar approach to Approach 1, where we iterate through each node in the grid, and as long as the node is not an element of the defined path, we block it with probably .
Maze
Mazes always have a start and end point in the top left and bottom right corners, respectively. We recursively carve out paths in the grid, chosing from some randomly selected direction, until our maze is generated.
Fixed Grids
I use 3 fixed variants that I was curious about, just as some baseline assurance.
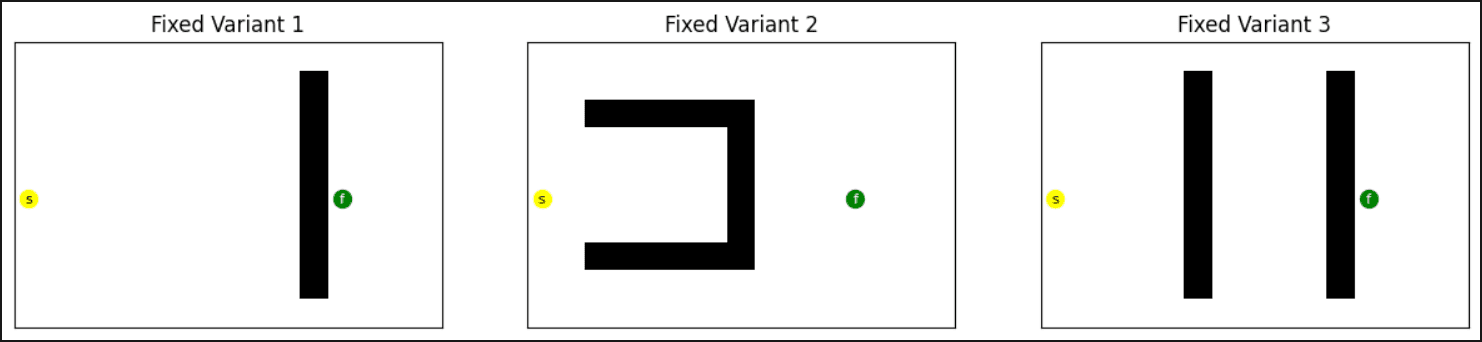
Simple First
First I'll introduce Breadth-First-Search (BFS) and Depth-First-Search (DFS).
I use iterative approaches, versus recursive, to make explicit use of data structures and have a more consistent approach throughout.
This get_neighbors() function that you'll see searches in the following directions, in order: UP, LEFT, RIGHT, DOWN
BFS
BFS is an exhaustive search, guaranteed to find the optimal path. It behaves as a diffusive search (conveniently named "breadth"), starting from the start point and iteratively expands outwards, regardless of where the target position is.
For BFS, we make use of a queue, which builds on the First-In-First-Out (FIFO) approach. We initialize the queue by adding the starting position. Until the ending position we found, we do the following:
- pop from the queue (FIFO)
- find VALID neighboring nodes
- for each neighbor, if we haven't seen it before, add it to the queue.
- continue until the popped node is equal to the end position.
Just a brief example of how the queue behaves in practice:
queue = Queue()
queue.put(2)
value = queue.pop()
# value = 2, queue = []
queue.add(3)
queue.add(4)
queue.add(5)
# queue = [3,4,5]
value = queue.pop()
# value = 3, queue = [4,5]In code, briefly:
queue = Queue()
queue.put(start)
parents = {start: None}
visited = set([start])
while True:
current_node = queue.pop()
if current_node == target_node:
break
for neighbor in get_neighbors(current_node):
if neighbor not in visited:
visited.add(neighbor)
queue.put(neighbor)
parents[neighbor] = cur_nodeThat's it, really. The key is the data structure involved. The queue.get() call dequeues the "oldest" node from the queue, and it uses it as our current basis of where to search from. The visited set is redundant, but I'll keep it in here, as we could've just searched parents.
I include this parents object in order to rebuild the optimal path. In order to do this, we can simply iterate through parents, starting from our target node, until our starting node is reached:
path = []
while node is not None:
path.insert(0, node)
node = parents[node]DFS
DFS searches as deeply as possible until the ending position is found, or there are no more available moves. If not found, and we run out of neighbors for a given node, we backtrack, keeping note to never visit the same node more than once. This is not guaranteed to find the optimal path, but we could get lucky and find the target position relative quickly.
For DFS, we make use of a stack, which builds on the Last-In-First-Out (LIFO) approach. We initialize the stack by adding the starting position. While it's a bit less straightforward to get the resulting path in BFS, as we have to rebuild it, in DFS the stack itself defines our path (although we do need to reverse it).
Just a brief example of how the stack behaves in practice:
stack = Stack()
stack.put(2)
value = stack.pop()
# value = 2, stack = []
stack.add(3)
stack.add(4)
stack.add(5)
# stack = [3,4,5]
peeked_value = stack.peek()
# peeked_value = 5
stack.pop()
# stack = [3,4]Until the ending position is found, we do the following:
- peek at the last element in the stack
- find VALID neighboring nodes for this "peeked" node
- for each neighbor, once we encounter a neighbor we haven't seen before, add it to the stack
- If there are no available neighbors, pop from the stack (backtrack), and continue as normal
- continue until peeked node equals the target node
In our case, we'll never see this as we guarantee that a path exists, but when the stack is fully depleted, it means that a path does exist and we can exit.
In code, briefly:
stack = Stack()
stack.put(start)
visited = set([start])
while not stack.empty():
current_node = stack.peek()
if current_node == target_node:
break
is_node_available = False
for neighbor in get_neighbors(current_node):
if neighbor not in visited:
visited.add(neighbor)
stack.put(neighbor)
is_node_available = True
break
if not is_node_available:
stack.pop()Comparison
We can compare the side-by-side behavior visually of the BFS and DFS algorithms. The blue dots denote the current searched node, and the eventual solid blue line are the paths found.
Note particularly how the DFS algorithm searches. Recall the order that neighbors are iterated through: UP, LEFT, RIGHT, DOWN. You can see this pattern take shape in real time. Further, darker blue dots denote backtracking of the DFS algorithm.
For this method, I used the random grid I described above (Approach 2), with a percent_block of 40%.


Just see how ineffective DFS is at the maze. It even directly passes the target to continue deeply searching other areas.
We can define this more accurately by running a search on a series of 10x15 grids. Each fixed variant is run once, since they never change. Each maze + random grid is ran 1,000 times. For the random grids, we vary the percent blockage. There are 3 metrics that I extract.
- Time: how long did it take to run
- Iterations: how many nodes were searched
- Length: resulting path length
Again, BFS is guaranteed to be optimal for path length.
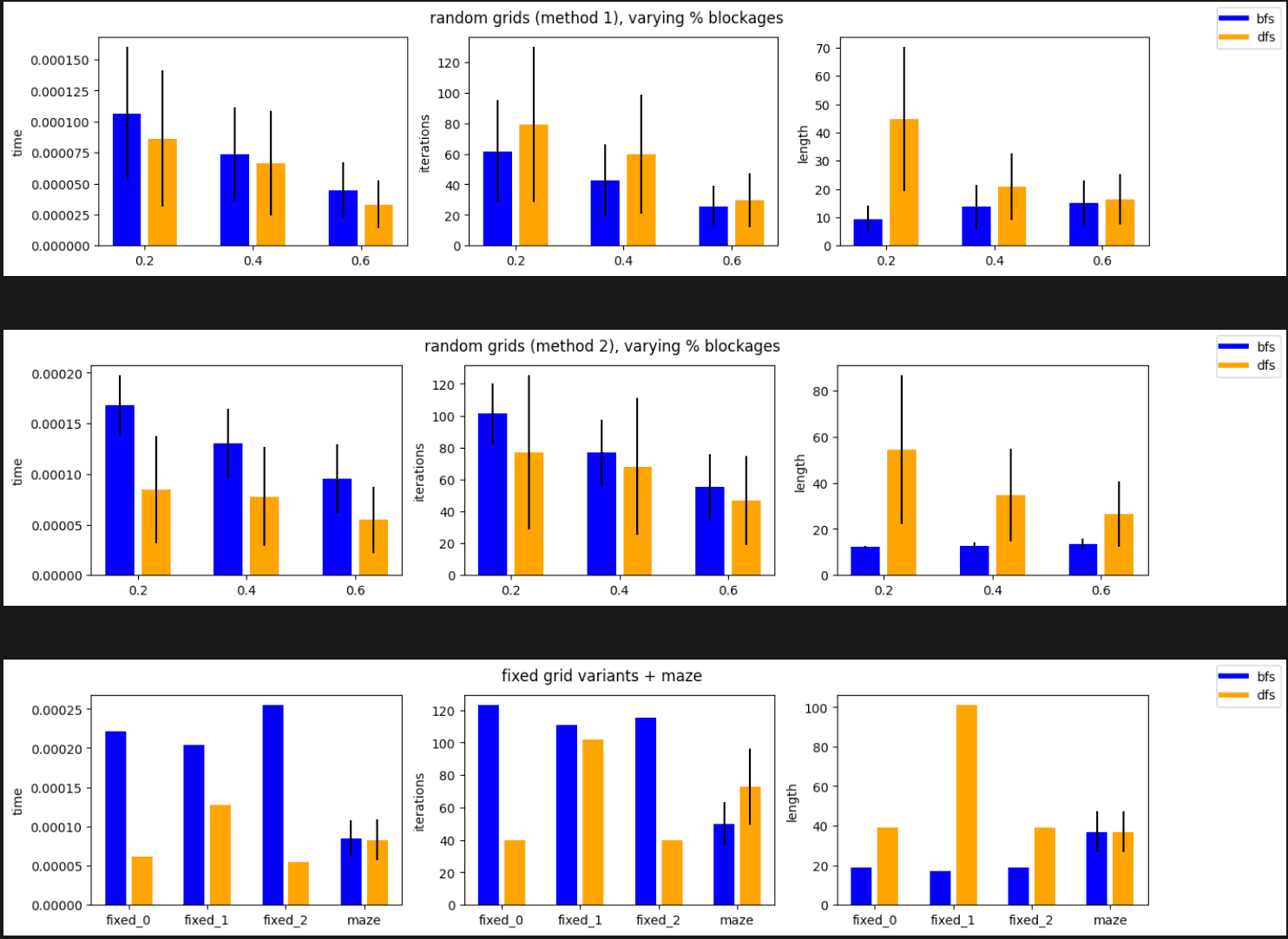
The results are quite interesting, but empirically seem to make sense. The maze tends to have very deep incorrect paths, that DFS tends to follow at first. The path length differential is quite drastic, but we can see the tradeoffs at time in speed and efficiency.
Heuristics
These BFS and DFS methods assume no knowledge of the target position, until it finds it. Surely we can add some heuristic to improve the search. For example, if we know the target is to the right of where we currently are, maybe we should prioritize a move to the right?
I'll introduce 2 new methods. One is Greedy Best-First Search. One, I'll define as a DFS with a heuristic (I believe I made this?).
Greedy BFS
Greedy BFS is nearly identical to BFS, except the data type used. In BFS, we use a simple queue: add nodes to a queue, remove them in the order you saw them. In Greedy BFS, we'll introduce a Priority Queue. Really, this can be implemented as a Heap data structure, but I won't get into that. I'll simply define the data type, rather than the explicit data structure.
With the added heuristic, we can tell the BFS algorithm to prioritize certain nodes over others, regardless of what order they were observed. The heuristic we use is Manhattan Distance to the target node. This means that the node we'll use as our current node will be the one that minimizes the distance to the target node, purely in terms of manhattan distance, even if it was the most recent node added to the queue.
start = (0,0)
target = (0,5)
queue = PriorityQueue()
queue.put((distance(start, target), start))
value = queue.pop()
# value = (0,0), queue = []
position = (0,1)
d = distance(position, target)
# d = 4
queue.add((d, position))
position = (1,0)
d = distance(position, target)
# d = 6
queue.add((d, position))
value = queue.pop()
# value = (0,1), queue = [(1,0)]We prioritize the node with the smallest distance. In code, briefly:
queue = PriorityQueue()
queue.put((0, start))
parents = {start: None}
visited = set([start])
while True:
current_node = queue.pop()
if current_node == target_node:
break
for neighbor in get_neighbors(current_node):
if neighbor not in visited:
visited.add(neighbor)
d = distance(neighbor, target)
queue.put((d, neighbor))
parents[neighbor] = cur_nodeThe heuristic is not giving any guarantees, it's simply a heuristic. Also, it's important to note that this method no long guarantees the optimal path.
DFS Heuristic
Similar to DFS, we search deeply. However, the neighbor that we elect to choose is no longer bound to the UP, LEFT, RIGHT, DOWN ordering (we could randomize this, but you get the point). Instead, in each iteration, depending on the node we're at, we select the best neighbor available to us that has NOT yet been observed. Backtracking is still used, and we certainly don't have guarantees of optimal path. However, we might see some speed ups empirically.
I won't highlight the data type used. It's identical to DFS in that we still use a stack. The only difference is that to order the neighbors in a given iteration, we use some heuristic (introduces some minor inefficiency per iteration).
Comparison
Let's compare these 2 heuristics with their DFS + BFS counterparts. Not bad, we see improvements in both. By chance, the target was UP and LEFT of the starting position, so the DFS heuristic performs similarly to DFS. However, we see drastic improvements in BFS by adding the heuristic.

Running the same analysis as previously, but with the 2 additional algorithms, we get the following:
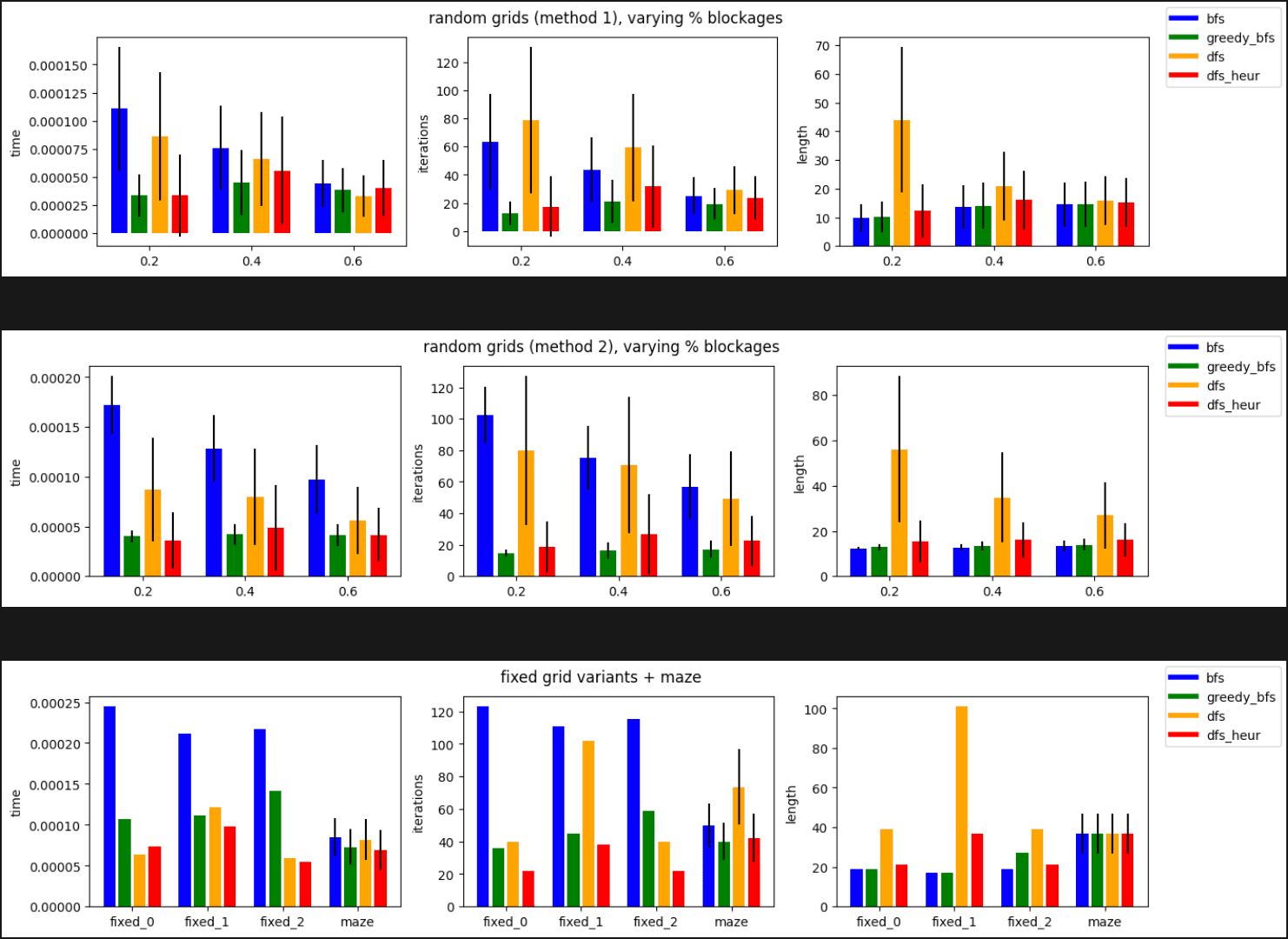
It's evident that adding this simple heuristic, and additional data type for Greedy BFS, leads to speed ups across the board. However, none of the algorithms are guaranteed to be optimal except BFS and its exhaustive search. We sacrifice drastic performance gains for the optimal solution. The DFS heuristic outperforms the DFS algorithm in time, # iterations, and resulting path length, on average.
Cost Function
Heuristics work well, but don't come with optimality guarantees. We can introduce the A star algorithm and compare its performance.
The basis of the A* algorithm are the costs of taking a move given your current position with respect to the starting and target positions.
- : The cost from the start node to the current node
- : The heuristic estimate of the cost from to the target node
- = G(n) + H(n)
Where is our evaluation function that we aim to minimize. Remember, our heuristic is simply the manhattan distance, so reduces to the manhattan distance between our node and the target. We can simply define as the cost to get to the current node of interest, by incrementing 1 to the cost of its parent.
We use a priority queue here, just like we did in Greedy Best-First Search. The algorithm changes to incorporate this cost as follows:
queue = PriorityQueue()
queue.put((0, start))
parents = {start: None}
visited = set([start])
g_costs = {start: 0}
while True:
current_node = queue.pop()
if current_node == target_node:
break
g_cost = g_costs[cur_node] + 1
for neighbor in get_neighbors(current_node):
if (neighbor not in visited) or (g_cost < g_costs[neighbor]):
visited.add(neighbor)
h = distance(neighbor, target)
f_cost = g_cost + h
queue.put((f_cost, neighbor))
parents[neighbor] = cur_node
g_costs[neighbor] = g_costWe introduced some additional logic. One is the g_costs object, which keeps track of the functional cost for a node. was simply our distance measure in Greedy BFS, which was originally used to dictate order in the priority queue. However, now, we introduced f_cost for the node, which becomes the value used to determine order in the priority queue. Lastly, we include an additional piece of logic. Instead of skipping if we've encountered the node, we say, if we've seen this node, but now reach it in a less costly manner, allow us to visit it again. This is important for ensuring optimality.
Comparison
Here's a comparison between the heuristic approaches and the A* algorithm:

Results
Lastly, we can do an exhaustive search between all methods, on varying grid sizes. For the purpose of displaying here, I'll only show the 20x20 grid, but you can see more on the github page in the exploration.ipynb notebook. For each of the random grids and mazes, I run 500 iterations, which admittedly is a bit low.
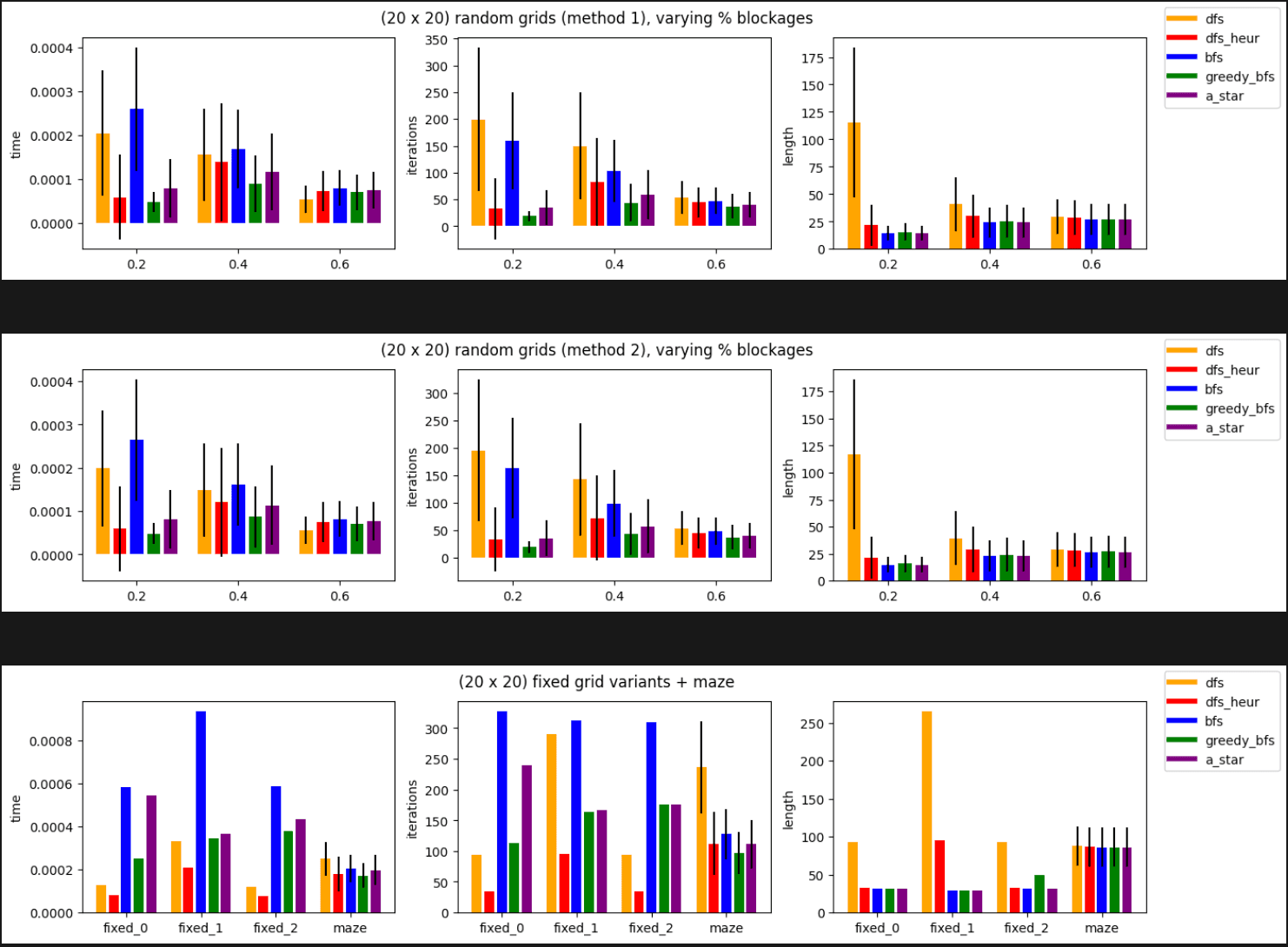
If our objective to find the most optimal path, it's clear that the A* algorithm is a drastic improvement to the BFS algorithm. It's even competitive with respect to the greedy heuristic methods, in many cases.
BFS really struggles with dense grids, as denoted by the low percent blockage random grids. DFS really struggles with Maze grid, which has deep but invalid paths. This shouldn't be horribly surprising, but it's interesting that this arises empirically. By chance in the Fixed grids, DFS finds the target incredibly quickly. These are simply there to highlight some expected issues with each algorithm, and see how they behave, versus inducing randomness. Adding a simple heuristic drastically helps on dense grids and mazes. A* seems to struggle quite a bit on dense grids as well, but excels on sparse grids, and regardless, we are guaranteed an optimal path. It seems like a great tradeoff between efficiency and optimality.
There are some additional performance improvements we can observe by introducing pre-processing on the graph or implementing jump search, for example, but I leave those out in this analysis.
I would consider a 20x20 grid to be small. Actually, incredibly small. For the purpose of this analysis though, I was generally interested in understanding some baseline behavior.
And to show these in action, exhaustively, here are the 3 fixed variants and a random grid for all algorithms mentioned (BFS completion is cut off intentionally in some).



